I recently launched a daft wee side-project to show people all the Number 1 songs on their birthday. To collect the data I had to scrape the Official Charts website as there was no official API available.
This article is going to explain how we can use Cheerio to scrape the site and gather all the information we need.
The full code for the site is available on GitHub
Requirements
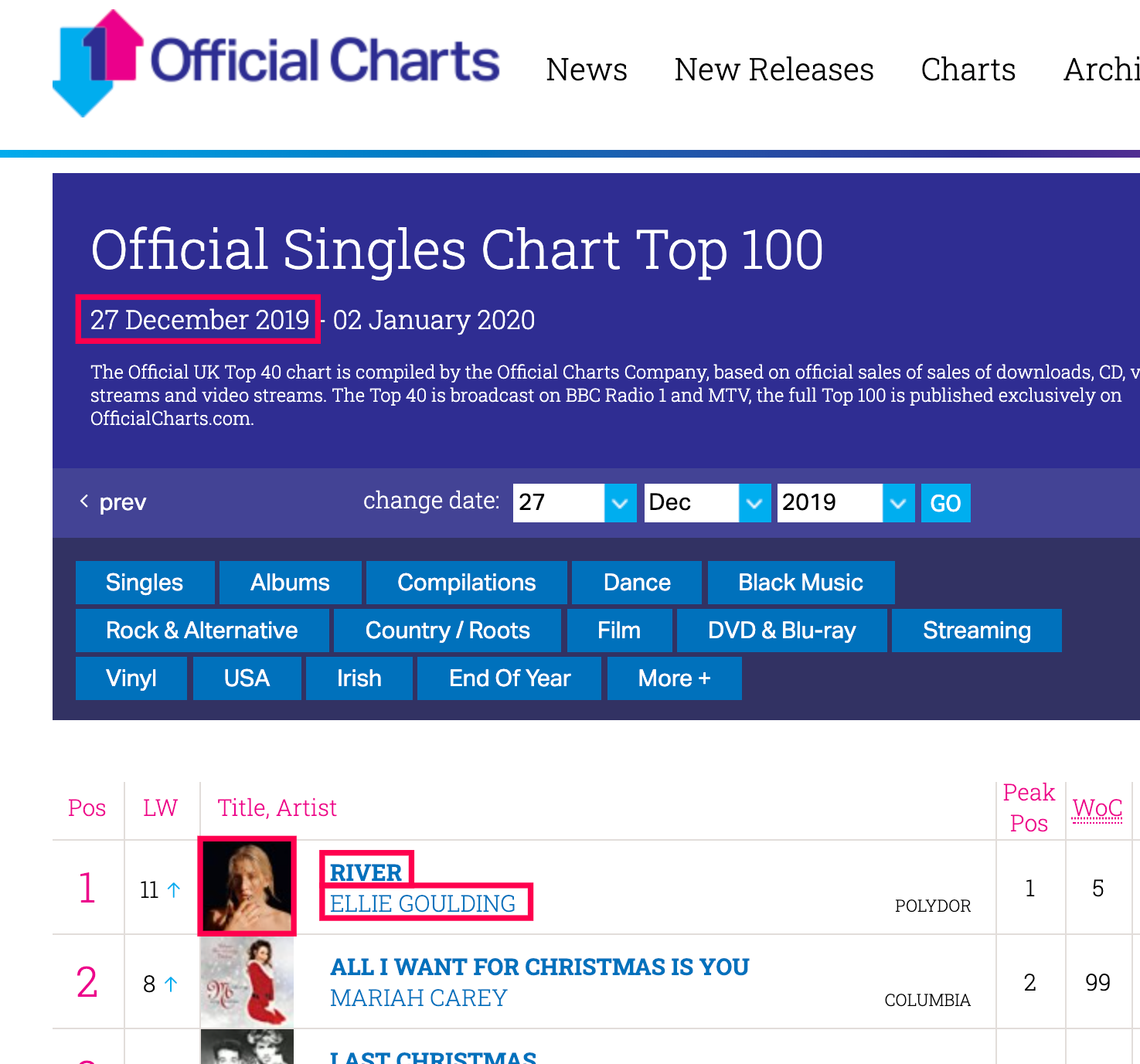
We're trying to grab the following 4 pieces of info (highlighted in the image below):
- the date of the chart
- the number 1 song name
- the number 1 artist
- the URL to the cover image
From the page which looks like this:
What is Cheerio?
Cheerio is a DOM manipulation library, essentially taking the jQuery interface and allowing it to be used on the server. This means that we can load in an HTML page and use jQuery like syntax to extract the bits of it we want.
What is Cheerio not?
Cheerio isn't a web browser and so doesn't interpret the page that is loaded in. It won't execute JavaScript or load external resources. It simply takes the HTML markup you give it, parses it and then lets you fiddle with it. For more complex web scraping projects, ones that require automated interactions and need the page to be loaded and rendered as it would be in a regular browser, then you would be better suited something like Puppeteer.
Why Cheerio over Puppeteer then?
Since all the info we want is in the raw HTML of the Official Charts page we don't need any interactions with the page. Using Cheerio to just parse this HTML is blazing fast and super simple.
To the Code!
First let's install the two dependencies that we need - axios and cheerio. We use axios to make our HTTP request to the Official Charts site to grab the HTML that we will parse. The cheerio package is then used to parse that HTML and provide us the interface to query it.
npm install axios cheerio --save-devNow that they are installed we can require them both into our script.
const axios = require('axios');
const cheerio = require('cheerio');Now we can make a request to our website and grab the response. In my case I was hitting a URL like this: https://www.officialcharts.com/charts/singles-chart/20200101 which shows the chart listings for that date. We use axios's get method and await for the response.
const axios = require('axios');
const cheerio = require('cheerio');
const url = 'https://www.officialcharts.com/charts/singles-chart/20200101';
const response = await axios.get(url);The response object has a data property which contains the markup that was returned. We use cheerio's load method to load in the HTML and we're ready to start querying it.
const axios = require('axios');
const cheerio = require('cheerio');
const url = 'https://www.officialcharts.com/charts/singles-chart/20200101';
const response = await axios.get(url);
const $ = cheerio.load(response.data);We give variable holding the parsed page the
$name so it is short and jQuery like.
Extracting The Date
We want to get the start date for this set of songs, which is contained in the following markup:
<p class="article-date">
27 December 2019 - 02 January 2020
</p>So we select it like we would with regular jQuery, using a CSS selector:
const date = $('.article-date');We can then extract the text content from it (the text() method), trim the whitespace off (trim()) and split it by the hyphen to get the start date (split('-')).
const date = $('.article-date');
const startEndDate = date.text().trim().split('-');
const startDate = startEndDate[0].trim();Finding the Song and Artist Name
Due to the structure of the HTML the number 1 song is not as simple to find. We need to use a more complex selector to find the first row in the table.
const track = $('.chart tr.headings + tr .track .title-artist .title').text().trim();
const artist = $('.chart tr.headings + tr .track .title-artist .artist').text().trim();Again we use the text() and trim() methods to get the text content and then tidy it up.
Getting the Cover Image
So far we've just grabbed text content inside elements, but just as jQuery can we can grab attributes from elements too. We want to get the URL to the cover image for the song so we first select the img element in question.
const cover = $('.cover img');Then we use the attr method to get the src value. Easy!
const cover = $('.cover img').attr('src');Taking it Further
That's a very quick intro to working with Cheerio and how I used it on the Birthday Number Ones project. If you're familiar with jQuery then you will not have trouble working with Cheerio. The docs are really comprehensive and have examples of just about every scenario you might need.
Happy scraping!